
Introduction
As mentioned in the previous post, a vast amount of information on Unicode is widely available so I won’t waste your reading time by repeating it here. What I will try to add is some additional explanations to fill in a few gaps, and reflecting the parts which I found a bit tricky to “pull together”. I am deliberately keeping these discussions “simple”, with due apologies to any experts reading this material.
Unicode: characters!
A fundamental idea/concept you will need to feel comfortable with, and which is at the heart of Unicode, is the notion of “characters”, at least the Unicode way of thinking about them. “characters” is one of those words for which most of us have some form of “natural understanding”, as used in day-to-day conversations. But any formal specification has to be rather more precise and provide definitions which can sometimes lead to confusion, because it complicates something which we think of as quite natural and simple and whose meaning we take for granted. For example, it would be quite natural to think of a and a as different “characters”: bold ‘a’ and italic ‘a’. But not so in Unicode: these are merely different visual representations of the same character, which Unicode calls LATIN SMALL LETTER A.
Unicode defines character as
“The smallest component of written language that has semantic value…”
You can think of a character as the fundamental unit, or building block, of a language; what it actually looks like when displayed on some device such as a screen or printout using a particular font is not relevant to Unicode: only the meaning is of interest.
Characters: names, numbers and properties
Each character listed in the Unicode Standard is assigned a formal name and assigned a number. However, although it is tempting to think of Unicode as just a long list of character names with a number attached to each one, the Unicode Standard is far more than this. If giving a character name and number is all that Unicode Standard offered, it would be a nothing more than a very large encoding of the world’s list of characters. The Unicode Standard goes far beyond this simple model.
The characters of a lanuage don’t all perform the same role; for example, in English (Latin script), there are characters for punctuation, digits as well as letters. So, in addition to a name and a number, characters are assigned properties, which are fully described in references listed in the Unicode Character Database (UCD). These properties are of course essential for use in computerised text processing operations such as seaching, sorting, spell-checking, bidirectional text algorithms and so forth.
Not all characters are designed to be displayed
This may sound strange but it’s true. Within the Unicode Standard are characters whose job is “to control the interpretation or display of text” so they do not have a visual form: they are there to provide information, typically for text-processing operations. With Arabic, for example, you may wish to force or prevent characters from joining, so Unicode provides special control characters to do this: the so-called ZERO WIDTH JOINER and the ZERO WIDTH NON-JOINER.
Unicode: the numbers game
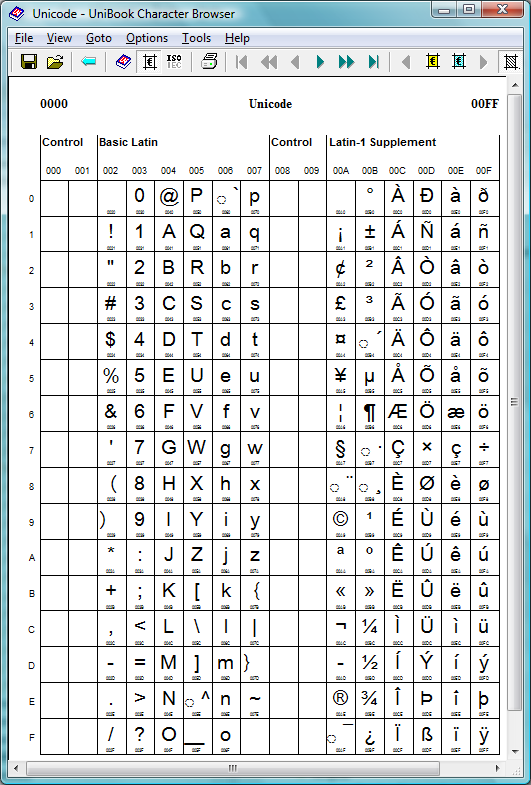
OK, let’s get closer to the goal of this post: UTF. As mentioned above, Unicode allocates each character a number and at present these numbers range from 0 through to 1,114,111 (0 to 10FFFF in hexadecimal), giving a maximum of 1,114,112 characters covered by the Standard. In Unicode-speak, each value between 0 through to 1,114,111 is called a code point. This range of 1,114,112 values (code points) is divided into 17 so-called planes, each plane containing 65536 code points (17 × 65536 = 1,114,112). Each plane is further divided into groups of code points called blocks. Full details are covered very nicely on Wikipedia.
For example, using the excellent UniBook™ Character Browser, you can see that the code point range 0000 to 00FF (hex) contains the blocks:
- 0000..007F = Basic Latin
- 0080..00FF = Latin-1 Supplement
A full list of the blocks can be downloaded from the Unicode web site.
UTF or Unicode Transformation Format
As the section title says, UTF stands for Unicode Transformation Format (or UCS Transformation Format). If you want to dive straight into the detail then Chapter 2 of the Unicode Standard General Structure (section 2.5) is the place for you. In this section I’ll try to condense this down into a simplified explanation.
As we’ve seen, Unicode assigns each character to a number in the range 0 through to 1,114,111. Now, one pretty obvious point, but I’ll mention it anyway, is that computers are in the business of storing and processing numbers. What we see as text is, ultimately, stored in memory or in a file as a sequence of numbers. Here, I’m going to simplify the discussion and only talk about whole numbers, called integers – actually just positive integers like 23, 675, not negative ones such as -56, -2323 etc. When a computer stores an integer it has a few choices, depending on how big that integer is: the smallest basic storage unit is the byte, but there are other storage types the computer can use. Again, simplifying… most common desktop computers can use storage units of 2 bytes, 4 bytes or more, but we’ll stick to storage units that are 1, 2 or 4 bytes in size. Here, when I refer to 2 bytes or 4 bytes I’m referring to indivisible units of 2 bytes or 4 bytes in size – not 2 or 4 consecutive 1-byte units stored end to end.
The point to note is that the maximum positive integer you can store in a 1-byte unit is 255, in a 2-byte unit it is 65535 and in a 4-byte unit it is 4,294,967,295. Hmmm, that’s interesting because the biggest number we need to store is 1,114,111, which clearly will not fit in 1 byte, and it is much bigger than 65536 so it won’t fit into 2 bytes. However, 1,114,111 is much smaller than 4,294,967,295, which is the next option, in 4 bytes. So, if we chose 4 bytes as our storage unit we certainly have more than enough room to store all the Unicode values, each one as a 4-byte integer. But this is very wasteful of space for a couple of reasons. Partly because the characters for many of the world’s languages and scripts are encoded in the first of the Unicode planes: Plane 0, or to give its proper name, the Basic Multilingual Plane or BMP, which needs just 2 bytes (see below) per character. To see a list of Unicode planes, check out this Wikipedia article. Storing Unicode code-points as 4-byte integers is also wasteful for all other planes because even the largest code points need a maximum of 21 bits, which means that 11 bits out of 32 would never be used.
As we said, each of the 17 Unicode planes, including the Basic Multilingual Plane, contains 65536 code points (Unicode character numbers) so the Basic Multilingual Plane, being the first one, contains the range 0 to 65535 or to use the conventional Unicode hexadecimal (base 16) notation: 0000 through to FFFF. Now, of course, a 2-byte storage unit is big enough to hold all those values and indeed you can work with that.
So, the real goal here is to find a way to store the Unicode code points (all 1,114,112 of them) such that you can save the Unicode text data values to a text file or process them in the computer’s memory. Clearly, you can store every code point as a 4-byte value. This is the simplest way to do it but wasteful of space. If you choose the method of 4-byte storage units (32 bits) then what you are doing is using a method called UTF-32. I’m not going to explore the 2-byte (16-bit) method called UTF-16 (as I have not studied it!) but skip straight to the next one down called UTF-8 because that is what LuaTeX uses.
Now, it may seem like there is a contradiction here. I just said that the biggest number you can store in 1 byte is 255, but the biggest Unicode code point is 1,114,112 and no way can you store that in 1 byte! However, through some clever thinking, you can still use a sequence of 1-byte storage units to represent numbers bigger than 255. And here’s where the Transformation in Unicode Transformation Format really becomes much more apparent: UTF-8.
Pingback: Unicode for the impatient (Part 3: UTF-8 bits, bytes and C code) « STM publishing: tools, technologies and change