In Unicode, the range (in hex) 0600 to 06FF is used for Arabic characters. Each value in the range 0600 to 06FF is referred to as a code point. In simple terms, just think of it as a number allocated to an Arabic character. For example, 0630 is allocated to ARABIC LETTER THAL (ذ). In advance of more detailed step-by-step tutorials I thought I would post a small C code program which will convert the 256 values 0600 to 06FF into UTF-8 encoding. The following C code will create a 512 byte UTF-8 encoded text file that you can open with BabelPad, for example. You can download the text file and C source here. I would not enter this code into a beauty contest but it is simple and works.
#include <stdio.h>
void main() {
unsigned short unicode_min = 0x0600;
unsigned short unicode_max = 0x06FF;
unsigned char arabic_utf_byte1;
unsigned char arabic_utf_byte2;
FILE * arabic = fopen("arabic.txt", "wb");
for(unsigned short p = unicode_min; p <= unicode_max; p++)
{
arabic_utf_byte1 = (unsigned char)(((p & 0x07c0) >>6) + 0xC0);
arabic_utf_byte2 = (unsigned char)((p & 0x003F) + 0x80);
fwrite(&arabic_utf_byte1,1,1,arabic);
fwrite(&arabic_utf_byte2,1,1,arabic);
}
fclose(arabic);
}
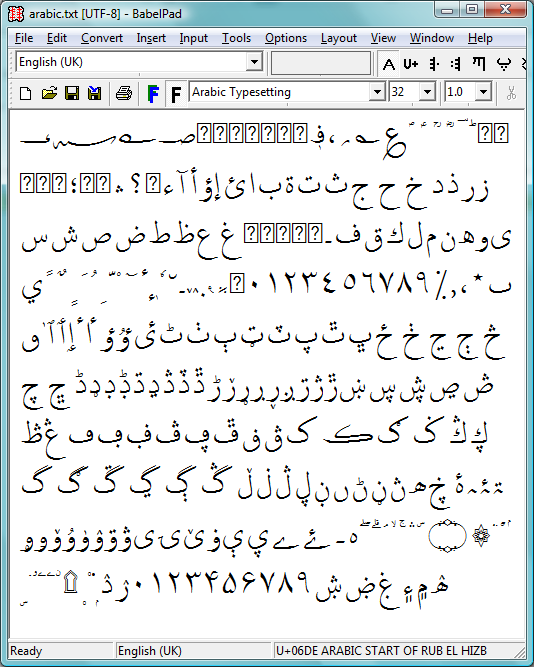
If you open arabic.txt in BabelPad you should see something like the following. Note, from within BabelPad you need to switch off complex rendering otherwise Windows’ Uniscribe shaping engine will be activated. In BabelPad, choose Options --> Simple Rendering. What you see will depend on the font you choose in BabelPad, the following uses the OpenType font “Arabic Typesetting” (shipped with Windows Vista). Of course, some code points do not correspond to actual characters or the Arabic Typesetting font does not have the appropriate glyphs: these are shown by a question mark (?) in a box.